

研究概要
データマイニングとビッグデータ解析
データマイニング (用語1) とビッグデータ解析の研究を行っています。近年のAIの発展を支えるビッグデータですが、利活用されるデータ量は全体に比べて実はほんの一握りです。このような有効活用されず眠ったままの膨大なデータから、これまでにない知識や洞察を得るデータマイニング技術を開発しています。
参考文献
- T. Phungtua-eng and Y. Yamamoto:
Adaptive seasonal-trend decomposition for streaming time series data with transitions and fluctuations in seasonality. Proc of ECML-PKDD (2024) - T. Phungtua-eng, Y. Yamamoto, and S. Sako:
Elastic data binning for transient pattern analysis in time-domain astrophysics. Proc of SIGSAC'23 (2023) - Yoshitaka Yamamoto, Yasuo Tabei, Koji Iwanuma:
Approximate-closed-itemset mining for streaming data under resource constraint - 山本泰生: 高次知識を獲得するリソース指向型オンラインマイニング法の開発
日本オペレーションズ・リサーチ学会, 62巻 pp. 246-252 (2017年)
研究助成
JST 可能性検証
(代表) ノイズフルな時系列情報から異常発生の予兆を捉えるデータ純化技術の開発 URL
科研費 基盤研究A
(分担) 広視野高頻度測光観測と異常検知による秒スケールで変動する宇宙の探査 URL
JST さきがけ研究 (ビッグデータ基盤領域)
(代表) 高次知識を獲得するリソース指向型オンラインマイニング法の開発 URL
大規模ストリームデータ処理
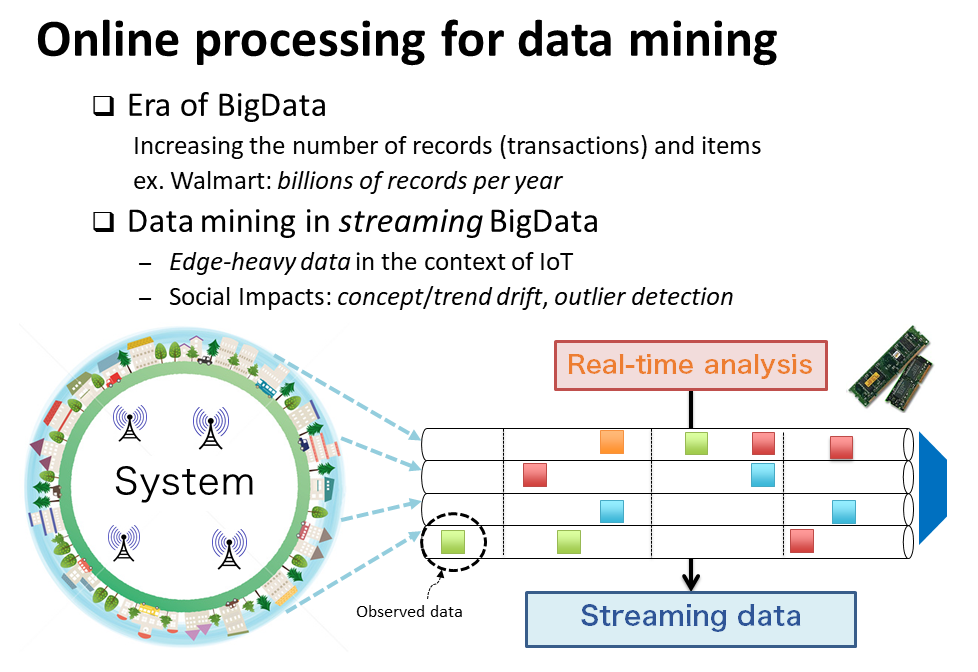
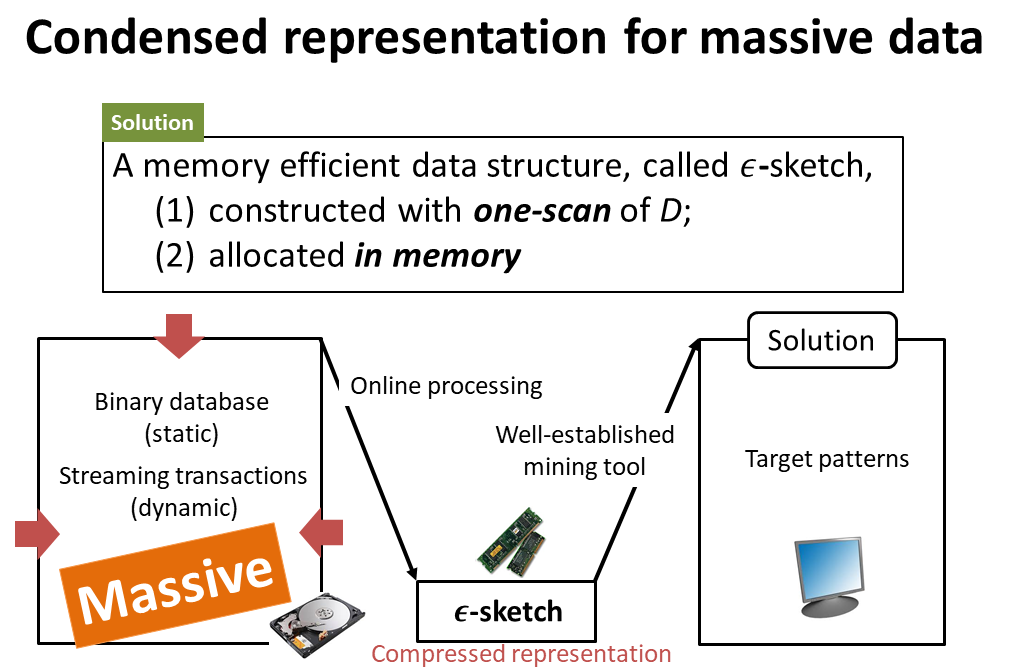
ストリーム型ビッグデータ (用語2) を対象とするデータ要約 (Sketching) 技術を開発しています。データ要約とは、対象データの出現分布を特徴づけるノンパラメトリック表現を指します。独立性や生成モデルなどの統計的前提に依らないデータ予測、学習に利用されています。クラウド-エッジ間の通信遅延がボトルネックとなる監視・観測システムへの応用が期待されています。
参考文献
- 山本裕介, 山本泰生: トランザクションデータストリームのサポートクエリに応答する劣線形サマリの構築
知識ベースシステム研究会資料 (2023年) - 山本裕介, 山本泰生: カーネル密度推定を用いた半順序サポートサマリの構築
知識ベースシステム研究会資料 (2021年) - 山本泰生, 岩沼宏治, 今井友輝: 半順序ストリームデータのサマリ構築
知識ベースシステム研究会資料 (2018年)
研究助成
科研費 基盤研究C
(代表) 高速・省メモリな半順序サポートサマリの開発と可用性検証 URL
(代表) 半順序関係に基づくストリームデータの劣線形要約 URL
(代表) オンライン近似圧縮に基づく次世代ストリームデータマイニング法の開発 URL
(分担) 潜在的相関ルール抽出を目的したオンライン型近似計算法の開発と仮説推論との統合 URL
発見の科学: 推論による仮説発見
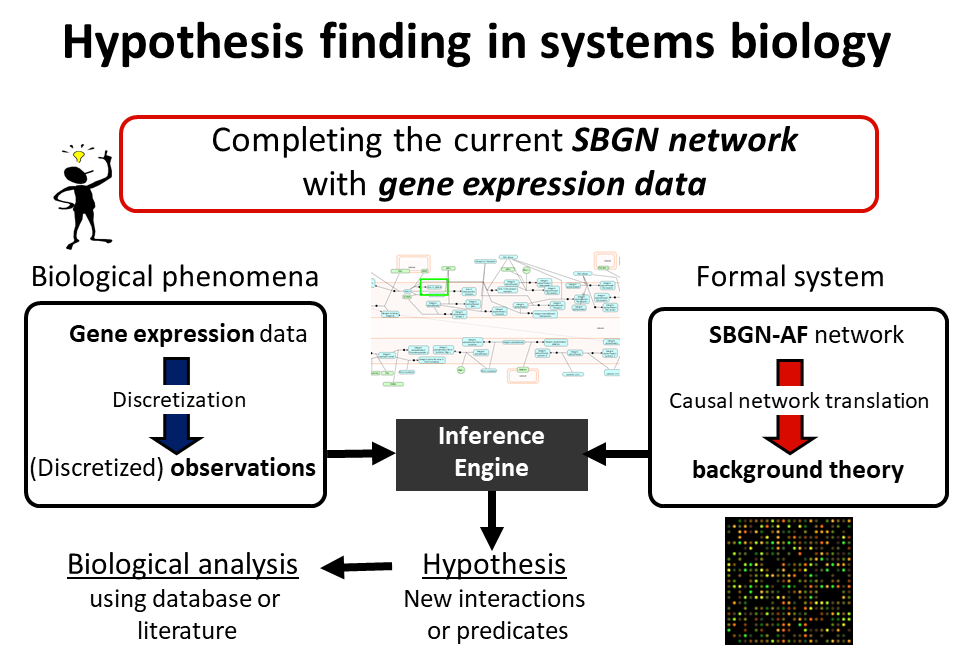
人工知能の基礎問題である帰納推論の研究を行っています。帰納推論とは、観測事実と背景知識から、新しい知識となる「仮説」を論理的に打ち立てる推論のことを指します。仮説を導出するための計算原理に関する基礎研究とそのシステムバイオロジー (用語3) 応用に取り組んでいます。
参考文献
- 福井凜, 山本泰生, 狩野旬, 坂井恵子: 深層学習による細胞の機能過程の同定–第2報–, 知識ベースシステム研究会資料 (2022)
- Yoshitaka Yamamoto, Katsumi Inoue and Koji Iwanuma:
Inverse subsumption for complete explanatory induction,
Journal of Machine Learning 86/1 115-139 (2011年) - Yoshitaka Yamamoto, Adrien Rougny, Hidetomo Nabeshima, Katsumi Inoue, Hisao Moriya, Christine Froidevaux, Koji Iwanuma:
Completing SBGN-AF networks by logic-based hypothesis finding,
Proceedings of the 1st International Conference on Formal Methods in Macro-Biology (FMMB2014), pp. 165-179 (2014年)
研究助成
科研費 基盤研究B
(分担) 新たな限界発現系gTOW2.0で解き明かす発現制約メカニズムの全体像
URL
科研費 挑戦的萌芽
(分担) 半導体デバイスを用いた電気刺激による細胞の分化誘導とそのメカニズムの解明
URL
科研費 若手研究B
(代表) 逆包摂法に基づく仮説推論の効率化とシステム生物学への応用 URL
(代表) システム生物学応用に向けた仮説枚挙システムの実現 URL
用語説明
- データマイニングとは
大量のデータに隠されたデータ中の規則・パターン・知識を抽出する情報処理技術です.ある店舗の商品購入履歴からどの商品とどの商品が一緒によく売れられているかを調べたり、株価相場から銘柄の変動を予測したり、気象データからモデルを構築したりする技術です。ビッグデータ時代のなかでますます重要性を増しています。 - ストリームデータとは
観測系から生成され続ける無限長のデータ系列のことです。クラウドサービスやIoT の発展に伴い、気象、小売、製造、インフラ、観光、医療、スポーツ等の分野で、多種多様なストリームデータが生み出されています。ストリームデータの特徴は、時間経過とともに蓄積されるデータ総量が急速に増加する点にあります。全データを保持し続けることは原理的に困難であり、データを「捨てる」ことが避けられません。すなわちストリームのデータ処理では、データを「上手に捨てる」ことが重要なポイントとなります。 - システムバイオロジーとは
遺伝子、シグナル伝達、代謝など、個々に取り扱われてきた系を一つの大きな生体システムとして再構築する生物学です。還元論的アプローチをとる分子生物学とは対照的なアプローチで注目されています。「ビッグメカニズム」に関連するプロジェクトが国内外で活発化しています。システムバイオロジー分野でも AI と IoT の技術展開と相まった進展が期待されています。